



Author: Olivier Mertzdoff
I was working on a recent archiving project for a global brewery company, I was asked this question and I thought I would share on this blog article.
Key facts:
- Archive is needed to reduce data volume for tables CE1xxxx, CE2xxxxx, and CE3xxxxx.
- COPAA_xxxx and COPAB_xxxx are the archiving objects to use.
- Data from COPAA_xxxx have to be archived first before those from COPAB_xxxxx.
- You archive by company code and by period if COPAA_xxxx and COPAB_xxxx uses multiple company codes.
In theory, you can archive by company code. As shown in the screenshot below, the fields for ‘Company Code’ and ‘Controlling Area’ are in variants to archive COPAA_xxxx and COPAB_xxxx.
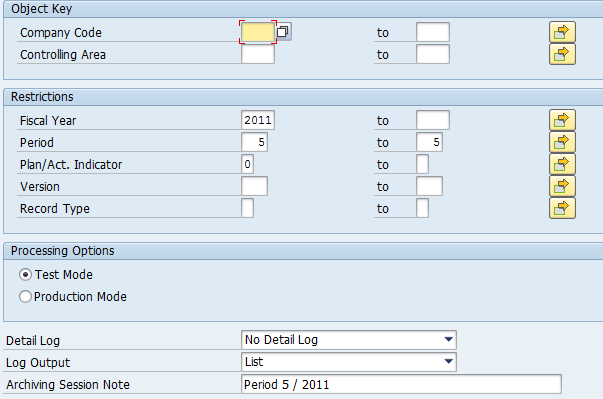
If you look at archiving program RK4Axxxx_WRI for COPAA_xxxx or RK4Bxxxx_WRI for COPAB_xxxx, there is no condition on company code in WHERE clause, only the period is tested.
Company code is only used when a test is done for a segment (i.e. table CE4xxxx linked to COPAC_xxxx object).
Let’s take a closer look at the number of records
Suppose you have 5 company codes with similar volume of data (i.e. 1 000 000 record for each company code):
If you archive for all the 5 company codes, the archiving job will read CE1xxxx and CE3xxxx tables only once for all company codes. Therefore, you will only have read 5 000 000 records.
- If you archive by company code, the archiving job will read CE1xxxx and CE3xxxx tables for each company code. More details of the job breakdown below:
- 1st company code, you will read 5 000 000 records
- 2nd company code, you will read 4 000 000 records
- 3rd company code, you will read 3 000 000 records
- 4th company code, you will read 2 000 000 records
- 5th company code, you will read 1 000 000 records
In total, you will have read 15 000 000 records.
You can see that the number of records to archive is multiplied by 3 when you set the archiving job by company code.
So how much time will that take?
This formula is probably the best way to show you:

n= number of company codes
| Company code (n) | Times longer to archive if by company code |
| 1 | Equal time to ALL company codes archiving job |
| 2 | 1.5 times longer |
| 3 | 2 times longer |
| 4 | 2.5 times longer |
| 5 | 3 times longer |
| … | … |
| 10 | 5.5 times longer |
| 20 | 10.5 times longer |
Based on the table breakdown above, it will not take you long to archive by company code if there are few company codes.
You can archive by company code if you have a few company codes and obtain optimized performances.
But with a lot of company codes, archiving performances will be better optimized if you archive all company codes together.
The answer to the question
In the case of my recent project and based on the above, we decided to archive company codes all together.
On the other hand, profitability analysis is key in transfer pricing, and transfer pricing is a hot topic (see BEPS topic in OECD as an example.). So you may want to segregate your archive job by company code, regardless of the additional running time.
Every solution is fine as long as the organisation makes an informed decision.
In all cases, whether you archive by ‘Controlling Area’ or by “’Controlling Area/company code’, the archiving process may end up quite complex for a large organization.
We use the TJC Archiving Sessions Cockpit (ASC) to get archiving done without burden. Below is a typical setup for this certified SAP add-on:
In ASC (Archiving Session Cockpit) software from TJC, if you archive all company codes together you will not need to define a specific archiving area for COPAA_xxxx and COPAB_xxxx object.
If you archive by company code (example company codes EX1 and EX2), you will archiving area EX1 and EX2 in /TJC/CP0 transaction:
![]()
Then in transaction /TJC/P06, you link your controlling area xxxx and company code EX1 or EX2 respectively to archiving area EX1 or EX2.
![]()
Then you define in /TJC/C02 and /TJC/C04 transactions archiving rules, for each archiving area:
/TJC/C04:
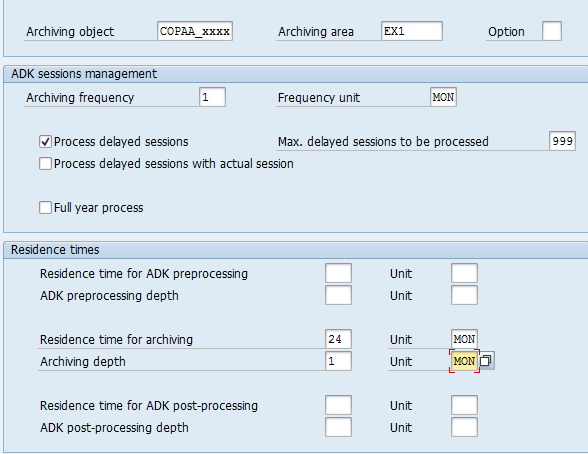
ASC creates automatically variants to archive COPAA_xxxx and COPAB_xxxx:
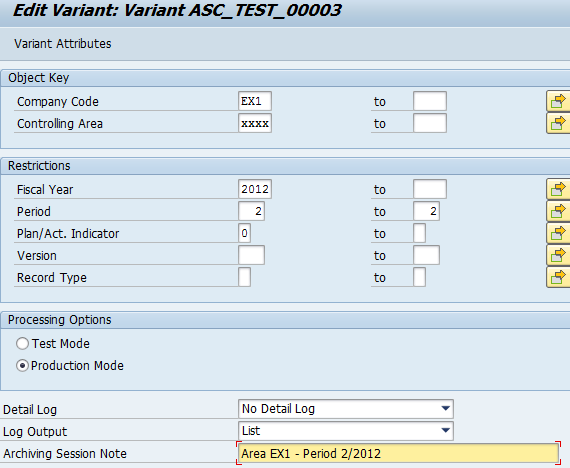
You can see “Archiving Session Note” filled by defined Area EX1 and considered archived period.
If you need further support with setting up Data Archiving sessions on the SAP system, get in touch with us: www.tjc-group.com.
")



