



Author: Jérôme Phillippe, Project Manager and Senior SAP ILM consultant at TJC Group
Introduction
Effectively sizing the HANA database is a critical aspect of SAP S/4HANA implementation, ensuring smooth operation and avoiding potential pitfalls. In this discussion, we explore the significance of memory management in HANA, methods to control database growth, and strategies to optimize SAP landscape costs.
It’s all about the memory
Sizing the HANA database is a crucial step in SAP S/4HANA implementation. If a classic database “becomes slow when data growth is out of control”, the HANA database will simply stop working! A simplified approach to calculating the memory requirements involves estimating data volume and growth for the upcoming years, then doubling the result (2TB of memory for 1TB of data). Running out of HANA memory can lead to complex upgrades – upgrading the license is not an easy piece – and increased licensing costs. That’s why it’s crucial to keep data volume growth under control.
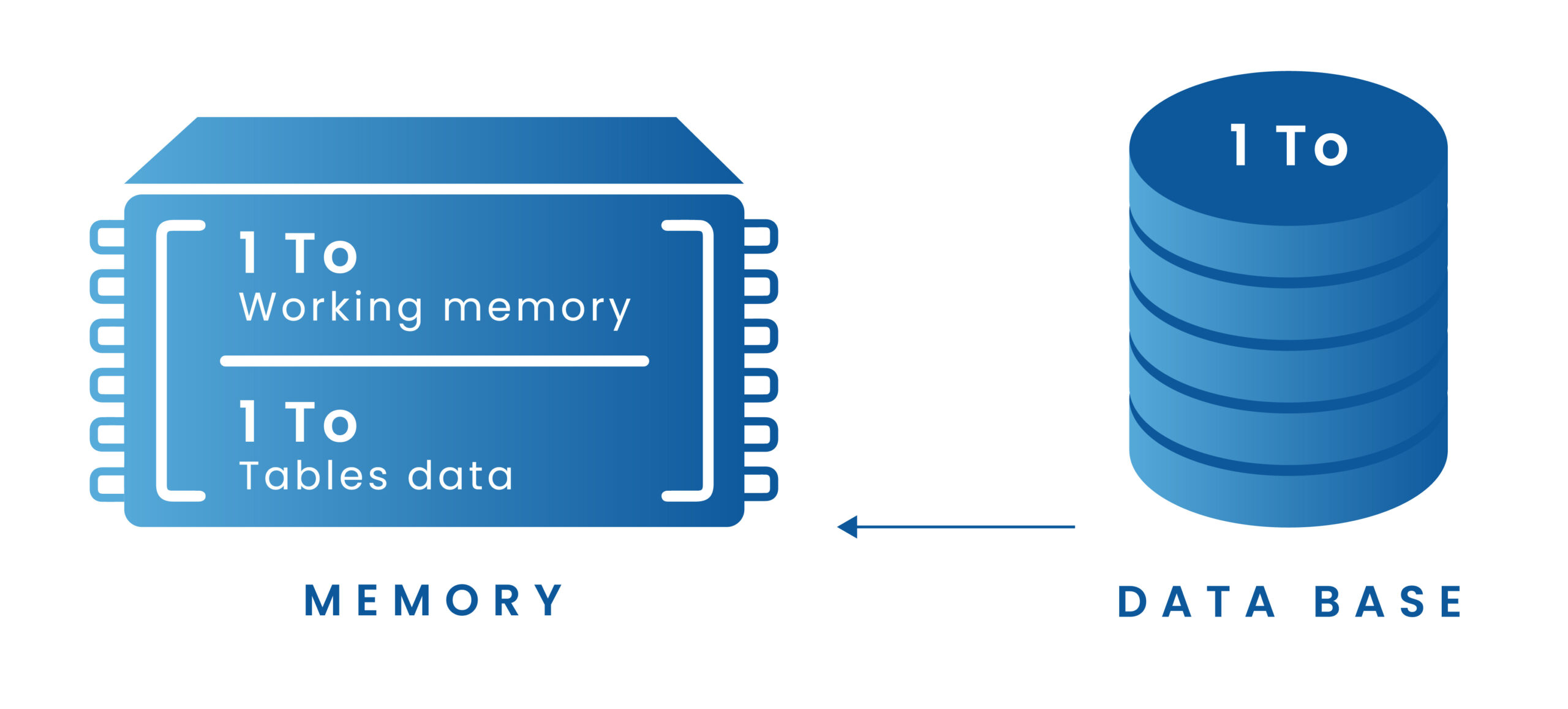
How is data managed in memory? What methods can be put in place to tame the database growth and, therefore, temper SAP landscape costs? Let’s see.
Managing Data in Memory: A story of “stores”
Understanding how data is managed in memory is crucial. The SAP HANA database supports two types of tables: Rows tables and Columns tables. Each table is loaded on its own “store” and, hence, they’re managed differently. SAP HANA is optimized for column storage, and this is the default table type in SAP S/4HANA.
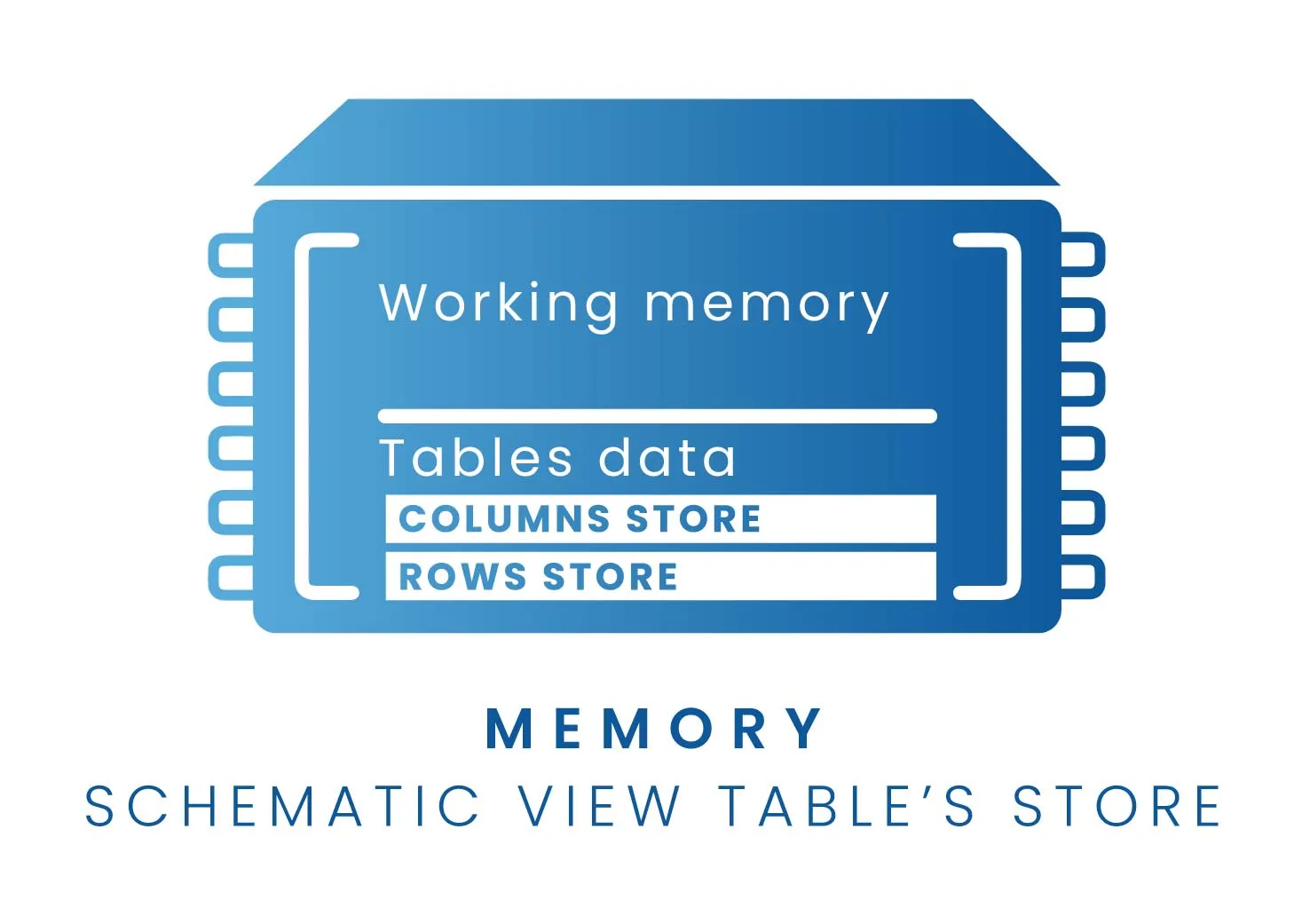
- Rows store
It’s quite a straightforward process. All the rows’ tables are loaded permanently in memory. If you wanted to decrease the impact on HANA memory, you would have to decrease the size of the tables. For some technical tables, regular housekeeping operations are required to avoid data inflation.
For functional tables (and some technical ones), data archiving makes total sense to dramatically decrease the data volume on the system without creating issues when accessing the data.
- Columns store
Column tables are strongly compressed. High compression rates can be achieved because the majority of the columns contain only a few distinct values (compared to the number of rows).
Column tables are loaded on demand (or at best, partially). So, why the concern? Every time that an update (an addition or a deletion) is carried out in a column table, the update is written in a temporary table (called a delta table). After a certain time or a certain amount of data, the original table is updated with the data from the delta table. However, for this operation, double memory is required (column table + delta table).
Overall, column tables will grow over time to support the company’s expansion. Find more information in the SAP HANA Administration Guide for SAP HANA Service: https://help.sap.com/docs/HANA_SERVICE_CF/6a504812672d48ba865f4f4b268a881e/bd2e9b88bb571014b5b7a628fca2a132.html
Dealing with the table growth
To tackle table growth, several strategies can be employed:
- Data Aging Considerations: Data Aging refers to removing part of the data that is stored within the SAP HANA database from HANA’s main memory. Please note Data Aging is irreversible and no longer recommended by SAP (note 2869647). Caution is advised due to potential complications as there is no way back.
- Regular housekeeping: Regular maintenance operations are vital for row tables to prevent data inflation, ensuring efficient database management. This includes many little jobs under the Database manager’s agenda such as cleaning old data, cleaning tables, etc.
- Native Storage Extension (NSE): For technical data and for logging data, it is recommended to directly use NSE. In a nutshell, the tables’ data is categorized into 3 different temperature tiers – Hot, Warm, and Cold- each of which is loaded/unload (or not) into memory in a different way in a dedicated buffer cache (SAP note 2799997). The Database Administrator can decide, after analysis, to put in place NSE for a table, an individual column, or a table partition. It’s worth noting NSE can be easily undone, if needed. This option is suitable for data that is not needed daily, only occasionally.
- Partitioning of column tables: Splitting large column tables into smaller, manageable partitions based on a specified key helps optimize memory usage. However, success depends on accurate partitioning specifications- what we call “the key”. If the user queries match the given key, it is possible to determine the specific partitions that hold the data being queried and avoid accessing and loading into memory partitions which are not required. On the contrary, if the query is based on over-selection (i.e. document type), all the partitions will be loaded in memory.
- Data Archiving: When archiving, the data is removed from the hard disk, preventing data from rising into memory, unless you decide to do so. The archive data is removed from the database and stored in a file system, which is a different storage, or it can also be stored in an external container that is linked to the system. Overall, it is a much cheaper storage and cost-effective.
All happy with SAP Archiving
When archiving data, the business users do not lose access to data, quite the contrary. Archived data remains available for display via the usual transactions (for instance tax and audit transactions). Data is stored in another place, in another format, but continues to be accessible as usual.
The Database Administrator retains control over data growth on disk and in memory and can continue to provide a high level of service to users.
The IT department keeps hardware and license costs under control regardless of business growth. Please note that HANA licenses are organized in steps, For example, if you have a 1TB license, when going over it, the next step is to buy another TB of memory, which is a huge increase. Indeed, it is not possible to buy 1.5TB or 1.2TB. The reader will relate to this, as in SAP ECC, with Oracle databases, it was possible to buy smaller storage units.
HANA is looking forward to SARA
SARA is the main transaction for archiving data, in other words, it’s the synonym of archiving. A few years ago, I remember reading a striking headline of a blog article:
“HANA will kill SARA”
Today, we know for certain this is not the case, mainly because data aging didn’t keep its promises. Data archiving (with or without ILM) remains the most efficient way to manage Information Lifecycle. That is why, here is my suggestion for a new mantra:
“HANA is looking forward to SARA”
Data Volume Reduction with the help of Archiving and SAP ILM should be a crucial phase in every data readiness strategy when preparing for S4/HANA Migration. It helps to reduce the data footprint and memory size of the SAP HANA database server.
Get support from Experts in SAP data Archiving and ILM to prepare & manage data for the S/4HANA move.
")

")

